Transformer-Based Emotion Recognition from Song Lyrics
November 2025 · Technical Deep Dive
Can transformers understand the emotions in song lyrics? In this research developed at CIIC/CISUC (University of Coimbra), we fine-tuned 8 encoder models and built an ensemble that achieves 77.43% F1-score on Russell's emotional quadrants — a 5.5% improvement over previous benchmarks.
Why Lyrics Matter for Emotion Recognition
Music Emotion Recognition (MER) aims to computationally identify the affective states conveyed through musical content. While most research has focused on acoustic features — tempo, key, timbre — there's a rich source of emotional information that's often underutilized: lyrics.
Think about it: when you hear "I will always love you," the melody carries emotion, but so do those words. Lyric-based Music Emotion Recognition (LMER) leverages the semantic and narrative content embedded in song lyrics to capture emotional expressions that audio alone might miss.
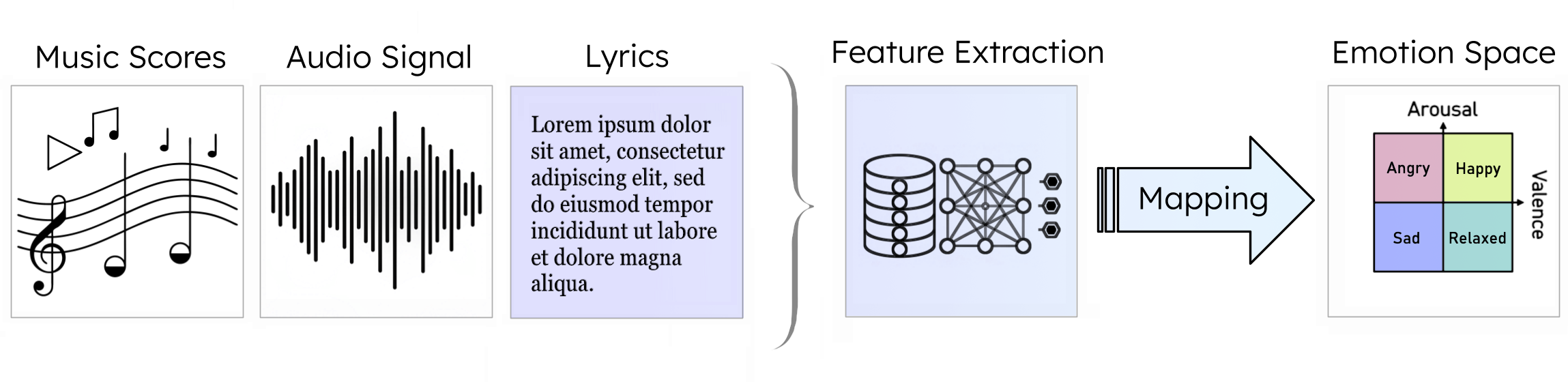
But LMER faces significant challenges:
- Manual feature engineering — traditional approaches relied on hand-crafted features like sentiment lexicons
- Metaphors and cultural references — "I'm on fire" doesn't mean what it literally says
- Long lyrics — many songs exceed the 512-token limit of standard transformers
This study evaluates whether modern transformer architectures can overcome these limitations through automated feature extraction and better contextual understanding.
The Evolution of LMER
LMER has evolved through three distinct phases:
Phase 1: Classical Approaches
Early methods combined text representations (Bag-of-Words, TF-IDF) with traditional ML algorithms (SVM, k-NN). Part-of-Speech tagging identified grammatical patterns associated with emotional expression; sentiment lexicons like ANEW (Affective Norms for English Words)[7] provided direct polarity mapping.
The limitations were significant: heavy reliance on manual feature engineering introduced bias, limited generalization across genres, and these approaches struggled to capture contextual emotional expressions — particularly when confronted with rhetorical devices, culturally-embedded references, and situational context.
Phase 2: Deep Learning
Word embeddings (Word2Vec, GloVe) transformed LMER by introducing automated feature learning — encoding emotional relationships in dense vector spaces without manual feature engineering. Recurrent Neural Networks, particularly Long Short-Term Memory (LSTM) networks, captured temporal dependencies within lyrics.
However, LSTMs have a practical limitation: context windows of approximately 200 tokens. This creates problems for songs with lengthy lyrics, where emotional narratives may span hundreds of words. Multimodal approaches combining audio and lyrics emerged during this period, showing that fusing complementary signals improves classification performance.
Phase 3: Transformers
Pre-trained language models like BERT and RoBERTa marked a paradigm shift. Self-attention mechanisms enable truly bidirectional context encoding, and encoder-only architectures are particularly well-suited for classification tasks.
Russell's Circumplex Model
How do we represent emotions computationally? We use Russell's Circumplex Model of Affect, which maps emotions using two dimensions:
- Valence: negative ← → positive (how pleasant the emotion is)
- Arousal: low ← → high (the energy or intensity level)
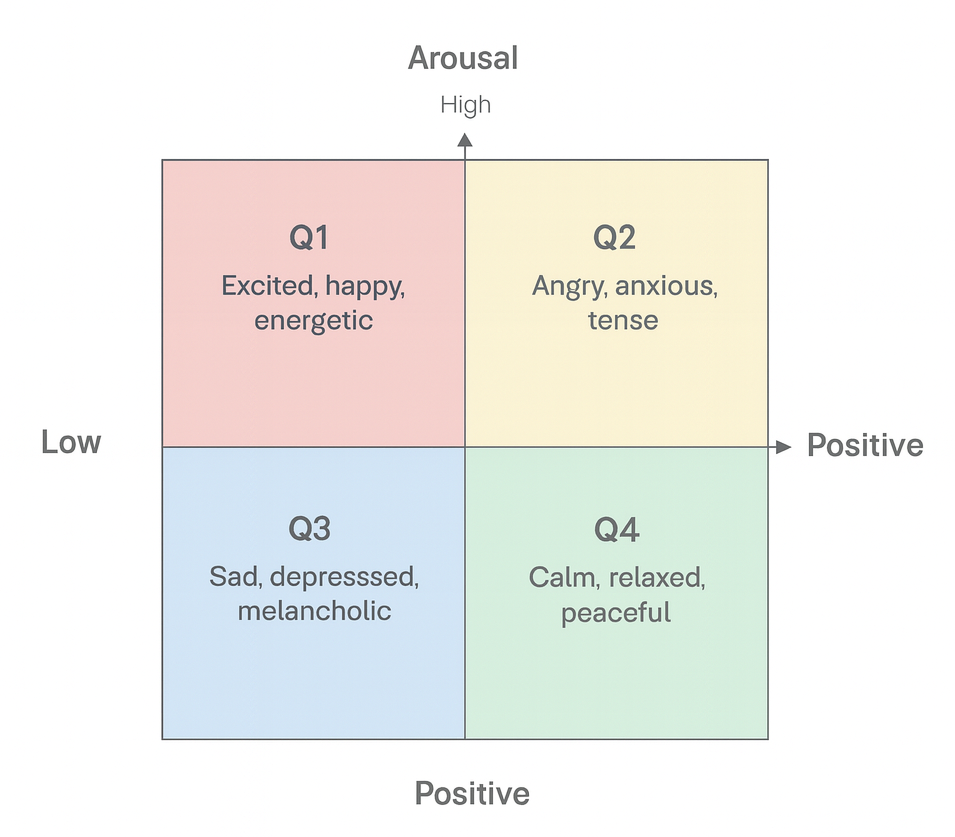
This quadrant approach preserves the dimensional model's depth while enabling discrete categorization — essential for supervised learning.
Methodology & Model Selection
Dataset: MERGE Lyrics
We used the MERGE Lyrics dataset[1]: 2,568 English songs annotated according to Russell's quadrants. This dataset was specifically designed for Music Emotion Recognition research and provides high-quality annotations:
- Manually validated annotations — no noisy automatic labels; human annotators assigned quadrant labels
- Balanced across quadrants — 600 samples each in the balanced version, addressing class imbalance issues common in emotion datasets
- Genre diversity — Rock, Pop, R&B, Country, Rap, Metal, Folk, ensuring the models learn generalizable patterns
- Publicly available — accessible on Zenodo (DOI: 10.5281/zenodo.10873009) for reproducibility
Model Selection
We selected 8 encoder-based transformers based on three criteria:
- Computational efficiency: models under ~450M parameters
- Established baselines: BERT, RoBERTa
- Extended context & architectural novelty: Longformer, DeBERTaV3, ModernBERT
| Model | Parameters | Max Tokens | Key Feature |
|---|---|---|---|
| BERT | 340M | 512 | Bidirectional baseline |
| RoBERTa | 355M | 512 | Dynamic masking, larger pretraining |
| DeBERTaV3 | 435M | 1024 | Disentangled attention |
| XLNet | 340M | 1024 | Permutation language modeling |
| BigBird RoBERTa | 400M | 1024 | Sparse attention |
| Longformer | 435M | 2048 | Sliding window + global attention |
| ModernBERT | 395M | 2048 | Novel positional encoding |
| ERNIE 3.0 | 296M | 2048 | Knowledge integration |
Training Setup
Each model was fine-tuned with:
- Optimizer: AdamW with weight decay 0.01
- Learning rate: Optimized via Optuna (range: 10⁻⁶ to 10⁻⁴)
- Epochs: 15 max, with early stopping (4 epochs patience)
- Scheduler: Cosine with warmup
- Runs: 10 per configuration (for statistical robustness)
The Truncation Problem
One critical challenge: many song lyrics exceed model token limits. When a song has 800 tokens but your model only accepts 512, what happens to the truncated content?
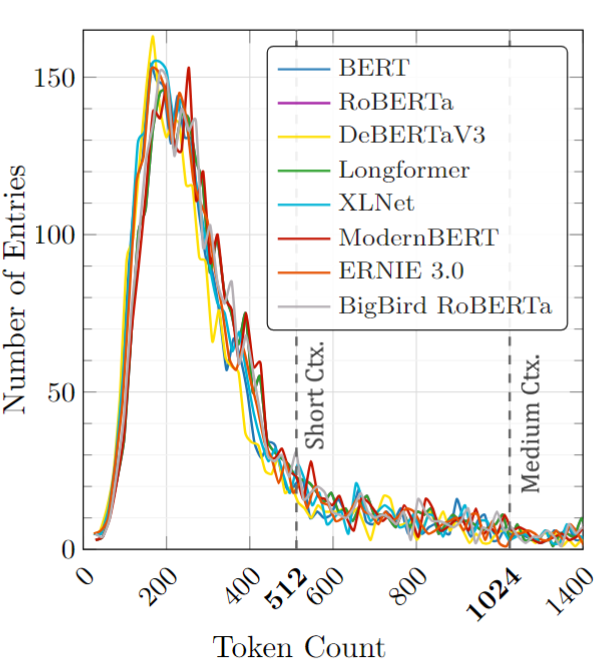
We analyzed truncation effects on the 70-15-15 split:
| Model | Truncated Instances | Error Rate on Truncated |
|---|---|---|
| RoBERTa | 61 | 6.56% |
| BERT | 56 | 8.93% |
| DeBERTaV3 Most Robust | 9 | 0% |
| XLNet Degraded | 10 | 50% |
| Longformer | 0 | N/A |
| ModernBERT | 0 | N/A |
Key Insight: Architecture Matters More Than Truncation Severity
Within each model, the degree of truncation doesn't predict errors (all p-values > 0.05). But which architecture you use matters enormously. DeBERTaV3 handles truncation gracefully; XLNet fails catastrophically.
Results & Analysis
Individual Model Performance
Macro F1-scores on the validation set (averaged over 10 runs):
| Model | F1 (70-15-15 Balanced) | F1 (70-15-15 Complete) | Std Dev |
|---|---|---|---|
| RoBERTa Best Individual | 76.20% | 75.86% | ±1.47-2.02% |
| ModernBERT | 75.95% | 76.06% | ±1.09-1.50% |
| Longformer | 75.93% | 75.94% | ±1.36-1.37% |
| BERT | 74.46% | 75.52% | ±1.36-1.38% |
| XLNet | 74.90% | 74.35% | ±1.15-2.23% |
| BigBird RoBERTa | 73.65% | 73.62% | ±1.57-2.62% |
| DeBERTaV3 | 73.18% | 71.24% | ±1.46-7.18% |
| ERNIE 3.0 | 69.08% | 71.82% | ±1.42-1.47% |
Key observations:
- RoBERTa maintained superior stability across all splits
- ModernBERT achieved competitive performance with extended context
- Longformer showed minimal variance (±1.36%) — very consistent
- ERNIE 3.0 underperformed by ~6-7% — its Chinese pretraining likely hurt English lyrics understanding
Quadrant-Level Performance
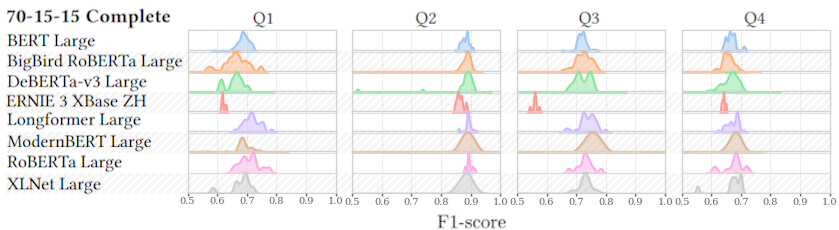
Interestingly, all models struggled most with Q1 (high arousal, positive valence) — the "excited/happy" quadrant. This might be because:
- Happy lyrics often use more indirect or metaphorical language
- Excitement can be confused with anger (both high arousal)
- Positive emotions may be expressed more subtly in lyrics
Ensemble: Better Together
Individual models have different strengths. Can we combine them?
We implemented a weighted soft-voting ensemble that combines probability distributions rather than discrete predictions. The weight for each model is computed using softmax over their validation F1-scores:
Then the ensemble prediction combines probabilities:
Ensemble Results
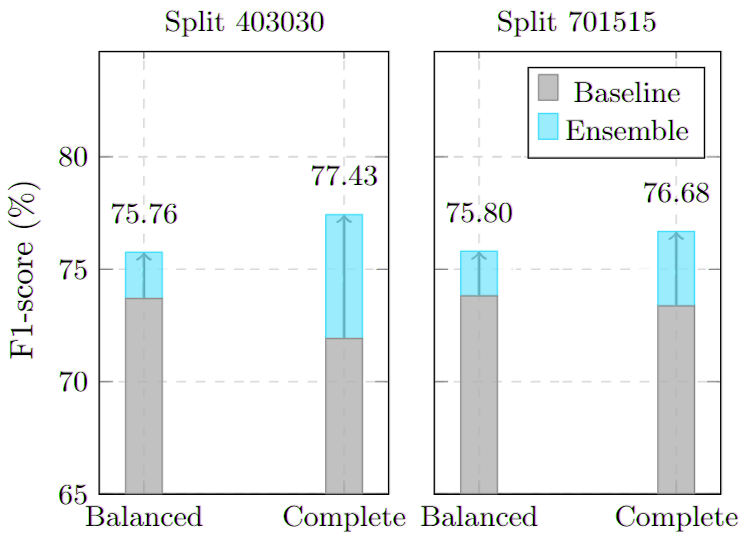
| Configuration | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| 40-30-30 Complete Best | 77.73% | 77.53% | 77.42% | 77.43% |
| 40-30-30 Balanced | 76.34% | 76.48% | 76.15% | 75.76% |
| 70-15-15 Complete | 77.08% | 76.97% | 76.54% | 76.68% |
| 70-15-15 Balanced | 76.12% | 76.35% | 75.58% | 75.80% |
Which Models Made the Cut?
The optimal ensemble composition varied by configuration, but some patterns emerged:
- RoBERTa was included in all ensembles (weight ~0.25)
- Longformer appeared in all configurations
- Weights were remarkably uniform (max difference < 0.06 within each ensemble)
- ERNIE 3.0 was never selected — its underperformance hurt ensemble diversity
The uniform weight distribution suggests that architectural diversity, not individual model dominance, drives ensemble improvements.
Key Takeaways
Transformers Work for LMER
Fine-tuned encoder transformers significantly outperform traditional approaches for lyric-based emotion recognition. RoBERTa emerged as the strongest individual model (F1: 75.57%).
Extended Context Helps (Sometimes)
Longformer and ModernBERT effectively handle long lyrics without truncation. But having more context doesn't guarantee better performance — model architecture matters more.
Truncation Robustness Varies Wildly
DeBERTaV3 handles truncation gracefully (0% error rate). XLNet fails catastrophically (50% error rate). Choose your architecture carefully if your lyrics are long.
Ensembles Beat Individuals
A weighted soft-voting ensemble achieves 77.43% F1-score — 5.5% better than previous benchmarks. Architectural diversity, not individual dominance, drives the improvement.
Happy Songs Are Hard
All models struggled most with Q1 (high arousal, positive valence). Detecting nuanced emotional intensity in "excited/happy" lyrics remains challenging.
Limitations & Future Work
This study focused on English lyrics from predominantly Western music. While the MERGE Lyrics dataset provides robust annotations, its focus on Western music may limit cross-cultural generalizability. Future directions include:
- Multimodal fusion: Combining lyrics with audio features for richer emotional understanding
- Multilingual models: Testing on non-English datasets (Portuguese, Spanish, Chinese lyrics)
- Decoder models: Evaluating GPT-style architectures with instruction tuning for emotion classification
- Explainability: Understanding which words, phrases, or linguistic patterns trigger emotion predictions using attention visualization
- Fine-grained emotions: Moving beyond 4 quadrants to more nuanced emotional categories
References
- Louro, P., et al. (2024). "MERGE: A Bimodal Dataset for Static Music Emotion Recognition." Zenodo. DOI: 10.5281/zenodo.10873009
- Russell, J.A. (1980). "A Circumplex Model of Affect." Journal of Personality and Social Psychology, 39(6), 1161-1178.
- Devlin, J., et al. (2019). "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding." NAACL-HLT.
- Liu, Y., et al. (2019). "RoBERTa: A Robustly Optimized BERT Pretraining Approach." arXiv:1907.11692.
- Beltagy, I., Peters, M.E., & Cohan, A. (2020). "Longformer: The Long-Document Transformer." arXiv:2004.05150.
- He, P., et al. (2023). "DeBERTaV3: Improving DeBERTa using ELECTRA-Style Pre-Training." ICLR.
- Malheiro, R., et al. (2017). "Emotion-based Analysis and Classification of Music Lyrics." International Journal of Multimedia Information Retrieval.
- Matos, B., et al. (2022). "Lyric-based Music Emotion Recognition using MERGE dataset." Proceedings of CMMR.
Acknowledgments
This work was developed at CIIC — Centre for Informatics and Intelligent Computing in collaboration with CISUC/LASI — Centre for Informatics and Systems of the University of Coimbra, Department of Informatics Engineering.
This research was supported by the Portuguese Foundation for Science and Technology (FCT) under the project UIDB/00326/2020.
Citation
If you reference this blog post, you may use the following citation:
@misc{Ribeiro2025TEMO,
author = {Ribeiro, Tiago F. R.},
title = {Transformer-Based Emotion Recognition from Song Lyrics},
year = {2025},
month = {nov},
howpublished = {\url{https://tiago1ribeiro.github.io/blog_posts/12_transformer_emotion_lyrics.html}},
note = {Blog post}
}
This blog post is based on research developed as part of ongoing work in Music Information Retrieval at CIIC. Questions or collaboration ideas? Reach me at tiago.r.ribeiro@gmail.com.