The Hidden Trade-offs of AI Development
Or: Everything Nobody Told You Before Putting an LLM in Production
December 2025
Introduction: The Conversation We Should Have Had
There's a certain dishonesty in AI demos. It's not lying, exactly — the system does what it shows. But it's like showing photos of London with only sunshine: technically true, practically misleading.
The dominant narrative goes like this: AI accelerates everything, solves complex problems with a few lines of code, and transforms mediocre programmers into 10x engineers. And there's truth in this. But there's also a second narrative, less glamorous, that emerges when you move from demo to production, from "look how cool" to "why is this costing €3,000 a day."
This article is about that second narrative. About the trade-offs that exist but are rarely discussed — not to scare you, but to prepare you. Because the difference between an AI project that works and one that collapses is almost always in the early understanding of what you're trading for what you're gaining.

The Speed That Deceives
What It Looks Like
Imagine you need to build a system that classifies support emails into "urgent," "normal," and "spam."
The traditional approach means weeks of work: mapping keywords, building heuristics, handling uppercase and lowercase, creative punctuation ("URGENTTTT!!!"), spelling mistakes, sarcasm, and that one customer who writes everything in caps lock but just wants to know about their tracking number.
With an LLM, you do this in an afternoon. You write a prompt, connect to the API, and it works. Magic.
What Happens Next
The magic lasts until someone asks: "Why are 12% of urgent emails being classified as normal?"
And here begins a journey the demos don't show.
You tweak the prompt. Improves to 9%. But now normal emails are being marked as urgent. You revert. Try another approach. Improves case A, worsens case B. Add examples. Improves B, introduces a new problem in case C (which you didn't even know existed).
Week 1: "Amazing, we shipped in 3 days!"
Week 3: "We're at 91% accuracy, we need 95%"
Week 6: "We've tried 47 prompt variants"
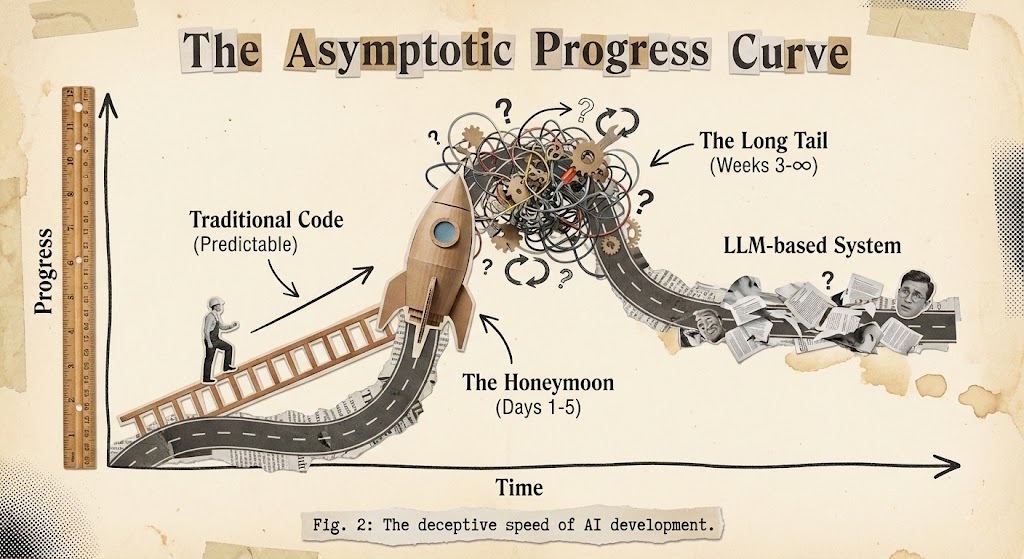
Week 8: "Maybe we should have used regex"The pattern is consistent: the first 90% is fast; the last 10% takes longer than everything else combined.
In traditional code, progress is (more or less) linear. You do X, you have X done. In probabilistic systems, progress is asymptotic. You approach the goal but each increment costs exponentially more effort.
This doesn't mean it's not worth it. It means that planning "we'll ship in 2 weeks" should be "we'll ship MVP in 2 weeks, then iterate for 2 months."
Generalization vs "I Wanted Exactly This"
The Beauty of Generalization
One of the genuinely magical things about LLMs is that they handle natural variation.
A rule-based system needs you to tell it that "urgent," "Urgent," "URGENT," "it's urgent," "super urgent," "kinda urgent but not really," and "I needed this yesterday" are variations of the same concept. An LLM just... gets it.
It's like the difference between explaining a joke to a computer (impossible) and telling it to a person (they laugh or they don't, but at least they understand it's supposed to be funny).
The Price of Generalization
The problem is that generalization means, by definition, loss of granular control.
Imagine this business rule: "Any email that mentions the CEO must be classified as critical. Always. No exceptions."
In traditional code:
if "CEO" in email.text:
return "critical" # Guaranteed. Sleep well.With an LLM:
Most of the time: works
Sometimes: "The competitor's CEO announced..." → critical (oops)
Rarely: "Meeting with John" [who is the CEO but didn't say so] → normal (oops)The LLM is doing what it knows: interpret context and decide. But interpreting context means, necessarily, there's room for interpretation. And room for interpretation means room for error.
The concrete dilemma: You can add deterministic rules on top of the LLM ("if contains 'CEO', force critical"). But each rule you add is a little bit of generalization you're taking away. Eventually you have a hybrid system where you no longer quite know who decides what.
(Documenting that boundary is important. Documenting that boundary is also the thing everyone promises to do "when we have time" and then never does.)

Debugging That Doesn't Feel Like Debugging
Traditional Debugging: A Satisfying Narrative
There's something deeply comforting about classic debugging. It's like a detective novel where the culprit is always caught.
- Bug reported: "The discount is wrong"
- Reproduce the problem ✓
- Stack trace points to line 47 ✓
- Inspect: variable 'rate' has wrong value ✓
- Find the error: condition was wrong ✓
- Fix ✓
- Tests pass ✓
- Case closed ✓
Time: 30 minutes to 2 hours. Satisfaction: high. Sense of control: intact.
LLM Debugging: A Russian Novel
Now imagine the same scenario, but with AI:
- Bug reported: "Classification is wrong for some emails"
- Reproduce... sometimes. Depends. It's complicated.
- Stack trace: there isn't one. The code didn't "fail," it just decided wrong.
- Inspect the prompt: looks correct.
- Check the context: the right documents are there.
- Test variants:
- Email A → "spam" (wrong)
- Email A with different comma → "normal" (correct?!)
- Email A without emoji → "spam" (wrong)
- Hypothesis: sensitive to punctuation?
- Test hypothesis: inconclusive results.
- Change prompt: improves case A, now case B is worse.
- Revert. Try something different. Check Stack Overflow.
- Question career choices.
Time: 4 hours to 3 days. Satisfaction: variable. Sense of control: absent.

The fundamental asymmetry: In code, the problem is somewhere in the code — it's finite, inspectable, fixable. In LLMs, the "problem" might be:
- In the model weights (inaccessible, trained by people you'll never meet)
- In the prompt (modifiable, but with unpredictable effects)
- In the context (controllable, but vast)
- In the statistical nature of the system (irreducible — it's a feature, not a bug)
It's like trying to debug a person. "Why did you respond like that?" "I don't know, it felt right." "But yesterday you responded differently." "Yeah, different vibe today."
Costs — The Bill That Arrives Later
The Wrong Mental Model
Most developers think about costs like this:
Traditional server: €100/month (fixed, predictable, boring)
Scaling: +1000 users = +€10/month (linear, comforting)And assume AI works the same, just with APIs:
LLM API: €X/month (equally fixed, right?)The Uncomfortable Reality
LLM costs are not fixed. They're variable, multiplicative, and occasionally surprising.
Cost per request: €0.001 to €0.10 (depends on model and size)Seems small, right? Let's do the math.
Scenario A: Simple chatbot
1,000 users/day × 5 messages × €0.01 = €50/day = €1,500/month. Acceptable.
Scenario B: Same chatbot, but with RAG
Each question now injects 5 context documents. Prompt 5x larger = cost 5x higher. €7,500/month. Less acceptable.
Scenario C: Autonomous agents
Each task requires 8 internal calls (reasoning, tool use, verification). 1,000 users × 5 tasks × 8 calls × €0.01 = €400/day = €12,000/month. You need a conversation with finance.
Scenario D: The viral tweet
Your product appears on Twitter/X. Traffic 50x normal for 3 days. €18,000 in unexpected costs. "Success" more expensive than you'd hoped.

What nobody warns you about:
- Retries are common. Malformed output? Retry. Timeout? Retry. Guardrail triggered? Retry with different prompt. Each retry multiplies cost.
- Prompts grow. RAG that starts with 2 documents ends with 10 "to improve quality." Each document costs.
- Success is expensive. If the product works, people use it more. Costs grow with success. (Cruel irony for startups.)
Necessary mitigations:
- Rate limiting per user (unpopular but necessary)
- Real-time budget alerts (before you need them)
- Aggressive caching of common responses (90% of questions are the same)
- Fallback to cheaper models under load
"Why Did You Do That?" — The Explainability Problem
When the Question Has No Answer
Imagine this dialogue:
Auditor: "Why did the system reject the loan for customer X?"
Traditional system: "Credit score 620 (minimum 650),
debt-to-income 0.45 (maximum 0.4),
2 late payments in the last 12 months."
Auditor: "OK, makes sense."Now imagine:
Auditor: "Why did the system reject the loan for customer X?"
LLM system: "The model assessed the profile as high risk."
Auditor: "Based on what?"
System: "...on patterns learned during training."
Auditor: "Which patterns? What features? What weights?"
System: "It's... complicated. There are 175 billion parameters."
Auditor: "That's not an answer I can put in my report."
The Real Problem
It's not just about audits. It's about trust.
When a traditional system makes a mistake, you can explain why. The error has a location, a cause, a history. You can point to the line of code and say "here, this condition was wrong."
When an LLM makes a mistake, the explanation is... statistical. "The model considered this response more likely than that one, based on patterns in training data we don't control." It's true, but it's not satisfying.
Regulatory implications:
- GDPR (Article 22): Right to explanation of significant automated decisions
- Financial regulation: Specific reasons for credit denial
- Healthcare: Justification for clinical recommendations
Mitigations (none perfect):
- Chain-of-thought: Force the model to "explain" its reasoning. Problem: the explanation might be post-hoc rationalization, not the actual cause.
- Hybrid with rules: LLM suggests, deterministic code validates and documents. Problem: if the code has the final say, what's the LLM for?
- Complete audit trail: Save everything — inputs, context, outputs. Problem: explains the what, not the why.
The honest answer is that some decisions shouldn't be delegated to unexplainable systems. Knowing which ones is part of the job.
Big Models vs Small Models
The Temptation of the Big Model
GPT-4, Claude 3.5 Opus, the big expensive models: they're better. Period. They reason better, fail less, handle edge cases more gracefully.
So why not always use the biggest?
The Cost of Being Big
| Aspect | Big Model | Small Model |
|---|---|---|
| Quality | Better, especially on hard cases | "Good enough" for simple cases |
| Latency | 500ms - 3s | 50ms - 300ms |
| Cost | €0.01 - €0.10 per request | €0.0001 - €0.001 per request |
| Complex reasoning | Excellent | Limited |
The cost difference is 10x to 100x. For a million requests per month, that's the difference between €10,000 and €100.
The Solution: Cascades
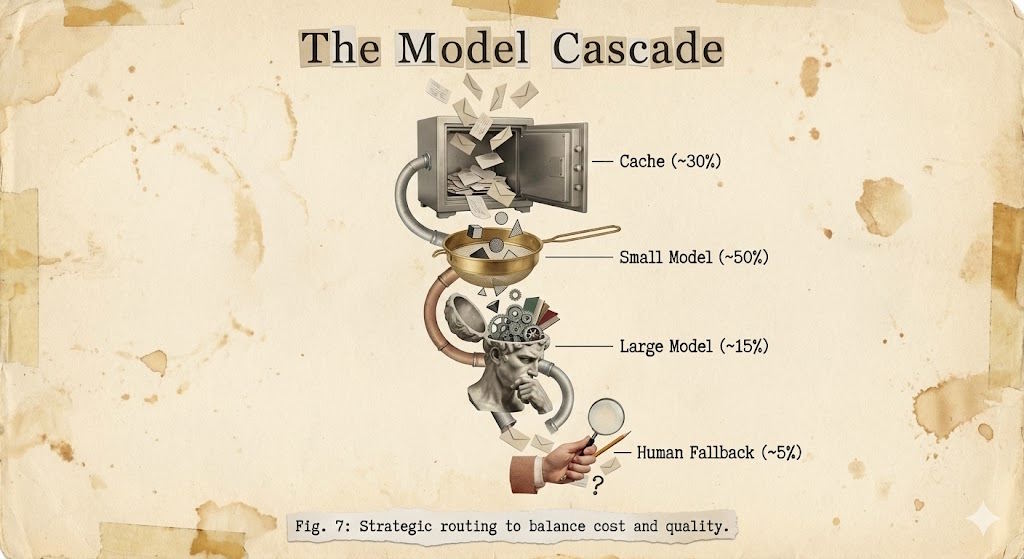
The mature approach isn't choosing one — it's using both strategically:
def respond(question):
# First: small, fast model for triage
classification = small_model.classify(question)
if classification.simple:
# 80% of cases: small model handles it
return small_model.respond(question)
if classification.needs_reasoning:
# 15% of cases: big model
return large_model.respond(question)
# 5% of cases: human
return send_to_support(question)The hidden trade-off: Now you have two models to maintain, two sets of prompts to tune, and routing logic that can also fail. You simplified costs, complicated architecture.
(It's almost as if there's no free lunch.)
The Meta-Trade-off
Visible Complexity vs Invisible Complexity
This is the trade-off that encompasses all the others, and perhaps the most important one to understand.
Traditional development has visible complexity. You open the codebase and there it is: thousands of lines, dozens of modules, hundreds of tests. Intimidating, but honest. The complexity doesn't hide.
AI development has invisible complexity. The code looks simple — sometimes dangerously simple. Three lines calling an API, a 200-word prompt, and it works. Elegant!
But the complexity didn't disappear. It migrated to:
- The statistical behavior of the model (which you don't control)
- The quality of the training data (which you probably don't know)
- The interactions between prompt, context, and model (which are emergent and surprising)
- The distribution of inputs in production vs development (which you only discover when it's too late)

The trap: Teams underestimate projects because the code "looks" simple. Managers assume "few lines = low maintenance." The reality is that the complexity is there — it's just less visible, and therefore more dangerous.
It's like that friend who seems relaxed and "low maintenance" but then has very specific opinions about restaurants, playlists, and the ideal room temperature. The complexity is there. You just didn't see it in the first few encounters.
Conclusion: The Art of Choosing Well
None of these trade-offs invalidates the use of AI. A hammer isn't bad because it doesn't work for tightening screws.
The problem is when we don't know we're trading something. When we assume AI is simply "better" instead of "different." When we plan for the demo and are surprised by production.
Maturity in AI development isn't about eliminating trade-offs — that's impossible. It's about:
- Recognizing them before you start
- Communicating them to stakeholders (who often think AI is magic)
- Designing systems that accommodate them consciously

The programmer who says "we're using AI because it's faster" is telling half the story — the beautiful half, the demo half.
The programmer who says "we're using AI for X because the benefits Y justify the costs Z, and we're mitigating with W" is ready for production.
And being ready for production, ultimately, is what distinguishes engineering from experimentation.
Demos show what's possible. Trade-offs show what's probable. Knowing the difference is what allows you to build things that work — not just on stage, but also in the real world, where people use software every day without knowing (or wanting to know) how it works inside.