Published on July 07, 2025
Feature selection is the systematic process of identifying and selecting a subset of input variables that contribute most effectively to the predictive accuracy of a machine learning model while reducing dimensionality and computational complexity. It is a critical step in preparing data for machine learning models. Its goal is to identify and retain only the most informative features from a dataset, eliminating those that are irrelevant or redundant. It is relevant for both supervised and unsupervised models, as reducing dimensionality can benefit clustering, visualization, and other unsupervised tasks as well.
This guide starts by identifying the most common types of features to eliminate before moving on to more sophisticated filtering and selection techniques.
Identifying Features to Remove
Before applying advanced selection algorithms, it is essential to remove features that, by construction or statistical nature, do not provide informative value to the model. These features fall into two main categories:
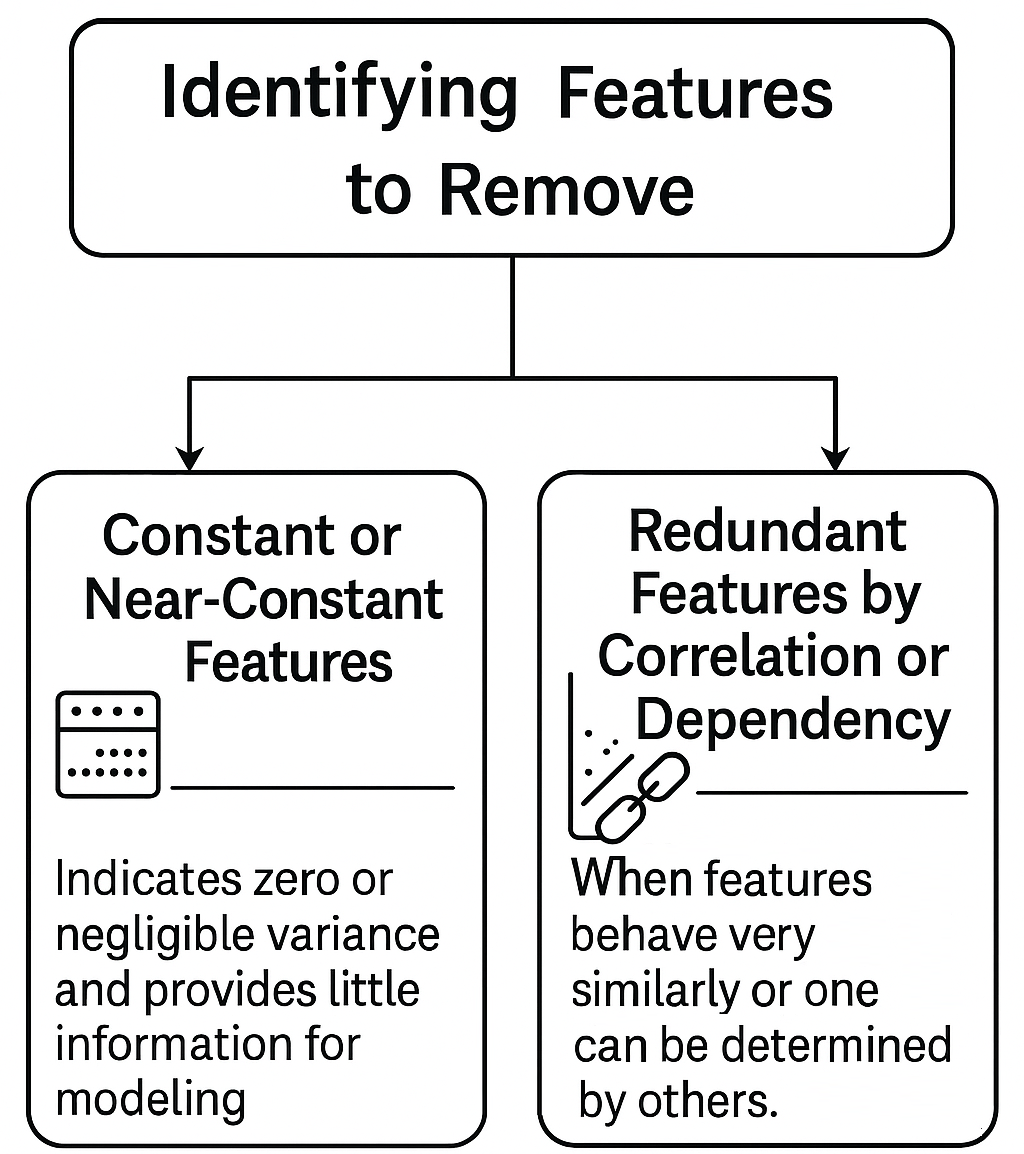
Constant or Near-Constant Features
Features that show the same (or almost the same) value across all samples have zero or negligible variance. Since they do not vary, they do not help distinguish between instances and should be eliminated upfront.
Additionally, features with a high proportion of missing values can often be removed at this stage, as they provide little information for modeling.
sklearn.feature_selection.VarianceThreshold can automatically remove features with variance below a threshold, typically between 1e-3 and 1e-2, depending on data scale.
Redundant Features by Correlation or Dependency
Redundancy can arise whenever two or more features behave very similarly or when one feature can be determined by others. The most common causes include:
- High correlation: Two features with a Pearson correlation coefficient |ρ| > 0.9 essentially provide the same information. For categorical variables, metrics such as Cramér’s V can be used to assess association.
- Multicollinearity: Occurs when a feature can be explained as a linear combination of others, measured by the Variance Inflation Factor (VIF). VIF values above 5 (or 10, for more permissive criteria) suggest unacceptable collinearity. [More]
Feature Selection Approaches
Feature selection can be performed using different strategies, grouped into three main categories: filters, wrappers, and embedded methods. Each has advantages and disadvantages depending on the problem context, project goals, and available resources.
| Filter Methods | Wrapper Methods | Embedded Methods |
|---|---|---|
|
General: Evaluate each feature independently using statistical properties (variance, correlation, independence tests). Selection occurs before model training, without involving the ML algorithm.
These methods are model-independent (do not use any ML model for selection).
|
General: Use a specific ML model to evaluate subsets of features by training and validation. The achieved performance guides the selection process.
|
General: Feature selection is integrated into model training. Some algorithms assign weights or importances, allowing automatic elimination of less relevant features.
|
Examples:
|
Examples:
|
Examples:
|
Pros:
|
Pros:
|
Pros:
|
Cons:
|
Cons:
|
Cons:
|
sklearn.feature_selection module provides several filter and wrapper methods for feature selection.
Feature Selection Pipeline
Feature selection is best structured as a clear, iterative pipeline. The diagram below summarizes the recommended flow:
In real-world projects, it is common to revisit and adjust steps based on validation results, iterating until satisfactory performance and interpretability are achieved.
- Data Preprocessing: Handle missing values, encode categoricals, normalize/standardize.
- Remove Irrelevant/Redundant: Drop constant, highly missing, or highly correlated features.
- Filter-Based Selection: Rank features by univariate metrics (e.g., mutual info, correlation, chi²).
- Wrapper/Embedded: Use model-based selection (e.g., RFE, LASSO, Random Forest importances).
- Cross-Validation: Evaluate model performance with selected features.
- Interpretation & Adjustment: Review selected features, adjust pipeline if needed.
- Note: Document all decisions for reproducibility and future reference.
Final Considerations
- There is no universal "best method": The choice depends on data type, dataset size, ML model to be used, computational resources, and objectives (performance vs. interpretability).
- Iteration: The process can be iterative. Start with filters, then apply wrappers/embedded methods on the reduced set. Cross-validation is essential at every decision point that could lead to overfitting.
- Domain knowledge: Expert knowledge about the problem can often guide the selection or removal of certain features, as well as the definition of thresholds.
- Impact of redundancy: Remember that redundant features not only increase computational complexity but can give undue importance to certain aspects of the data and destabilize some models.
- Documentation: Documenting the process and the rationale for each decision is crucial for reproducibility and interpretability of the results obtained.